In this article, we’ll show you how to activate your proxy package and start using it.
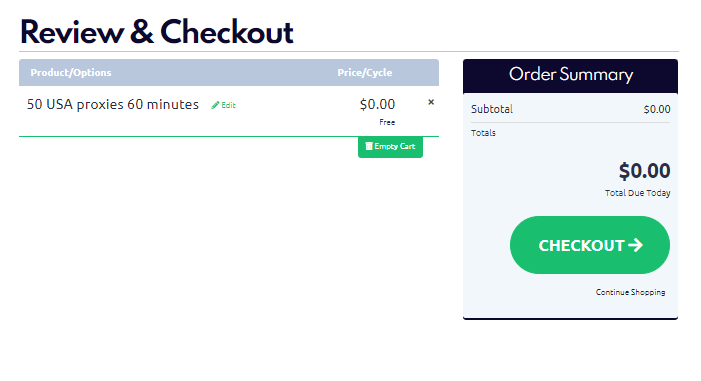
Step 1: Add the Test Package to Your Cart
If you've already paid or received a link to a free proxy package, you're ready to proceed. Otherwise, you can find the test proxy package link on this page: https://proxycompass.com/free-trial/.
Click the link to add the test proxy package to your cart, then click the “Checkout” button.
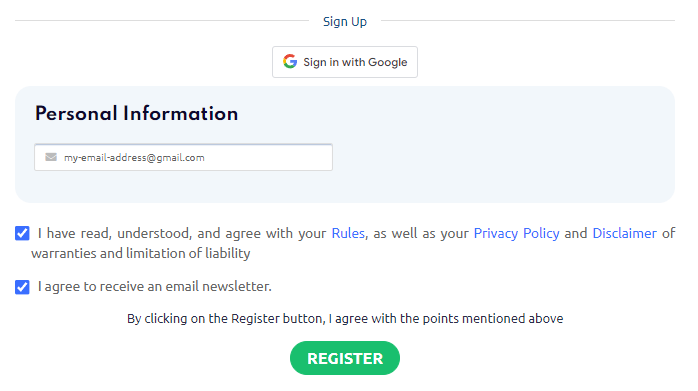
Step 2: Register on the ProxyCompass Service
Use your Google account or enter your valid email address. Click the “Register” button to complete the registration process.
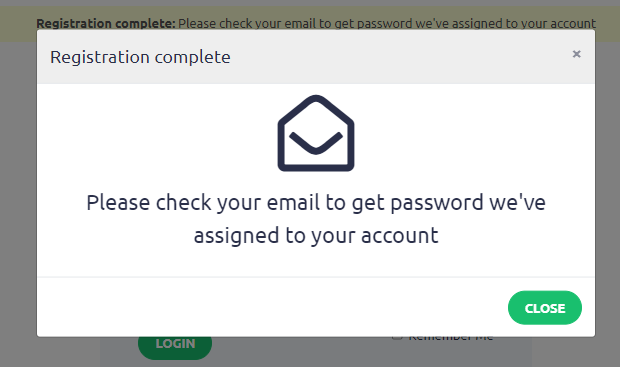
Your registration is complete. The password for your new account has been sent to the email address you provided.
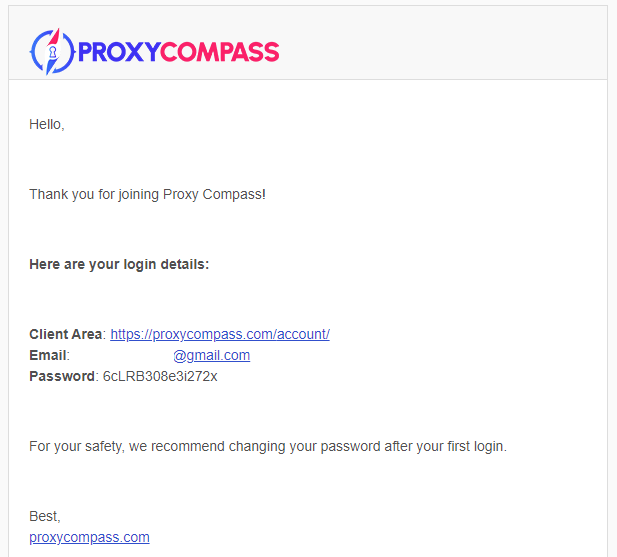
Step 3: Check Your Email
In the email you received from us, you will find an automatically generated password. You can change this password later.
Step 4: Log in to the Dashboard
Go to the link:
https://proxycompass.com/account/index.php?rp=/login
Enter your previously provided email address and the received password. Click the “Login” button.
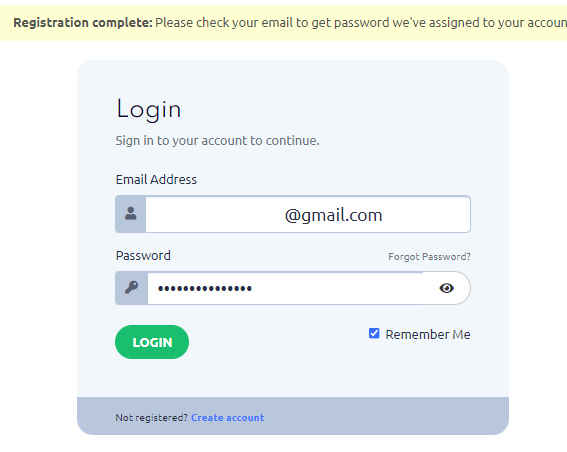
Click the “Cart” button to proceed with the activation of the test proxy package.
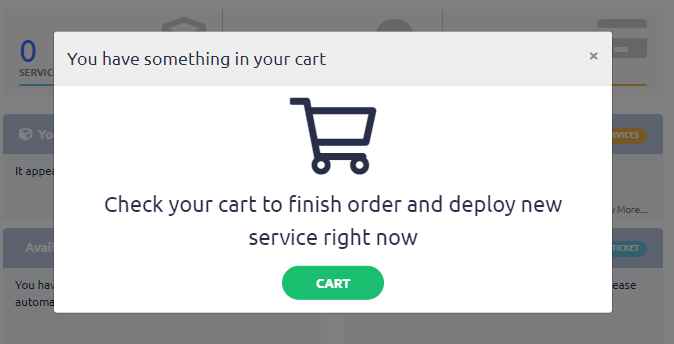
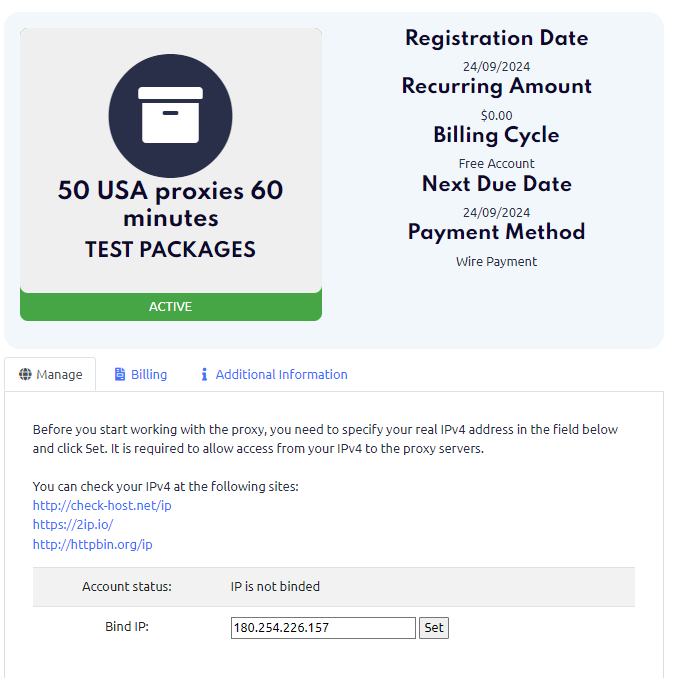
Step 5 (Important): Enter Your Own IP Address in the “Bind IP” Field
Be sure to enter the IP address of the device where you'll use the proxies. The proxies will only be accessible from the device with the IP you specified in "Bind IP".
For example:
- For a home computer, enter your home computer’s IP.
- For a remote server or VPS, enter the server's IP.
Visit https://2ip.io/ to find your current device’s IP.
In most cases, the IP will auto-fill. Click “Set” to apply settings.
Note: Activation may take 5-10 minutes. Just be patient.
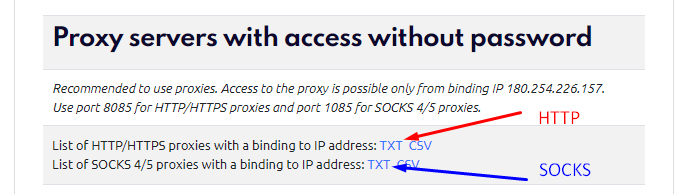
Step 6: Choose the Suitable Proxy Retrieval Option
- Download an HTTP or SOCKS proxy list in the IP:PORT format.
- Download an HTTP or SOCKS proxy list in the IP:PORT:Username:Password format.
- Get a random SOCKS proxy via the link.
- Get a random HTTP proxy via the link.
- Generate and download a proxy list in a custom format.
How to Download a Proxy List (Without Username & Password)
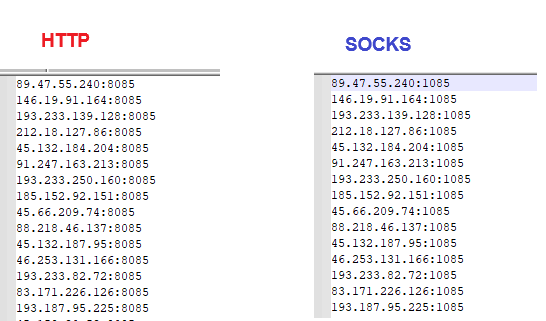
If your program uses proxies without authentication, download the text file in the IP:PORT format.
In this case, use port 8085 for HTTP or 1085 for SOCKS.
To download the list in this format, click the “TXT” link as shown in the screenshot.
You will receive proxy lists in the following format:
How to Download a Proxy List with Username and Password
Your proxy Login and Password can be found at the top of the page. It will be displayed as follows.
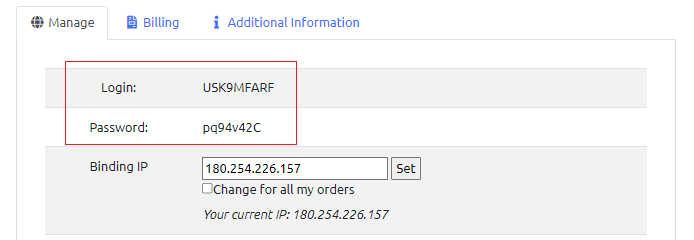
In our example, our Login is USK9MFARF, and the Password is pq94v42C.
If your program requires the proxy list in the format IP:Port:Username:Password, follow these steps:
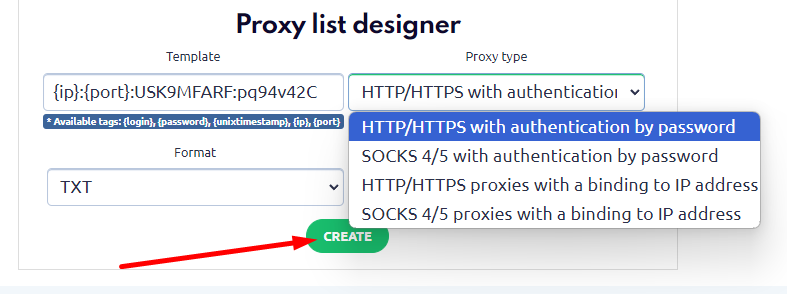
Scroll to the bottom of the page to the "Proxy list designer" section.
Enter the following code in the "Template" field:
{ip}:{port}:USK9MFARF:pq94v42C
Replace this sample login and password with your actual credentials
where:
- {ip} - each IP address in the proxy list
- {port} - required port
- USK9MFARF - sample login
- pq94v42C - sample password
Select the desired option in "Proxy type" and click "Create" to generate the proxy list.
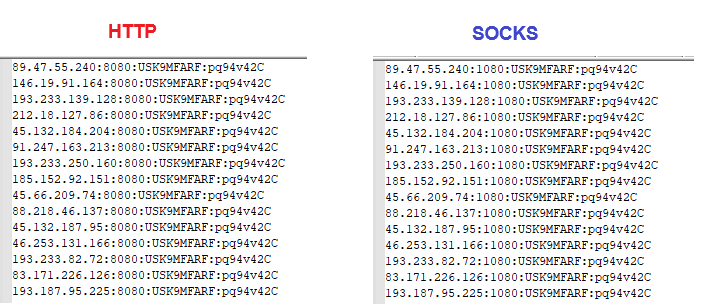
As a result, you will get a generated proxy list in the required format: IP:Port:Username:Password.
How to Get a Random Proxy from the List Without Downloading
If your program doesn’t support proxy lists and requires a direct link to a specific proxy server, you can do the following:
On the service page, find the section titled:
API for remote access to single random available proxy
You will see the following options there.
Click the “Get” link next to the option suitable for your program to obtain a random proxy from the list.
- Random HTTP Proxy without login/password:
https://proxycompass.com/api/getproxy/?r=1&format=txt&type=http_ip&login=YOURLOGIN&password=YOURPASSWORD
- Random SOCKS Proxy without login/password:
https://proxycompass.com/api/getproxy/?r=1&format=txt&type=socks_ip&login=YOURLOGIN&password=YOURPASSWORD
- Random HTTP Proxy with login/password:
https://proxycompass.com/api/getproxy/?r=1&format=txt&type=http_auth&login=YOURLOGIN&password=YOURPASSWORD
- Random SOCKS Proxy with login/password:
https://proxycompass.com/api/getproxy/?r=1&format=txt&type=socks_auth&login=YOURLOGIN&password=YOURPASSWORD
Replace YOURLOGIN and YOURPASSWORD with your actual login credentials.
https://proxycompass.com/knowledge-base/how-to-activate-a-proxy-package/