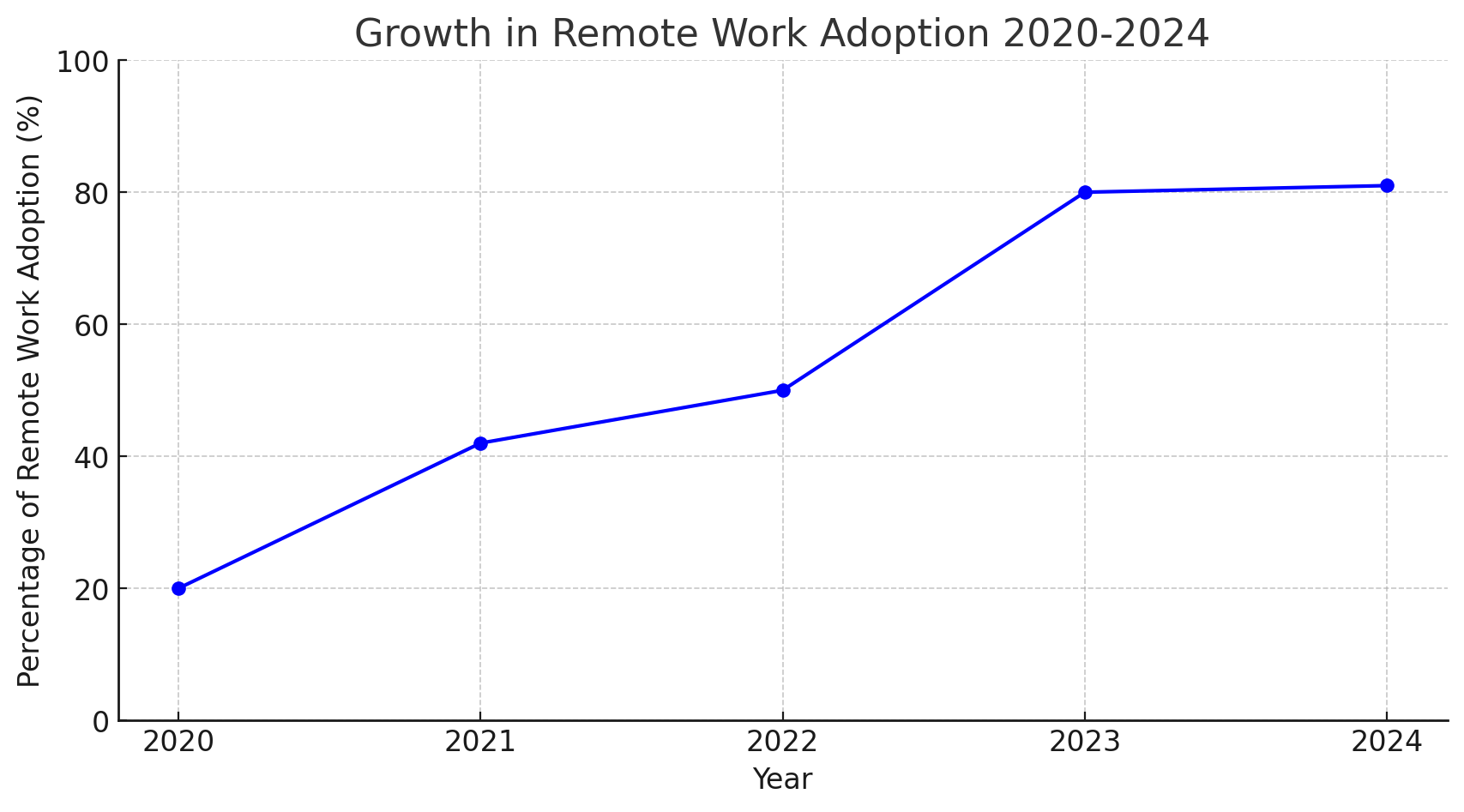
The high-profile case of hiQ Labs Inc vs LinkedIn Corporation (that took place in the US) shed light on the much-discussed data scraping legal issues.
We know you don’t want to get lost in legalese.
So, we have prepared an easy-to-read summary of the most important points of this decision. The court sided with the scraper and established that scraping public data is not a violation of the CFAA (Computer Fraud and Abuse Act).
Let's look at the specifics of the case, and also the far-reaching consequences it left.
Is Web Scraping Legal?
What did the web scraper say when asked about his legal strategy? "I plead the 404th."
If you're new to scraping data, you're likely concerned about the legality of your actions.
Good news is that you are not alone. Every scraper (I think?) has wondered the same.
Bad news is that the answer is not so simple. Like dating, it just refuses to be simple.
Web scraping falls in a gray area and it can be an ambiguous practice.
Of course companies want to preserve their data, but, on the other hand, if it’s publicly available, why is it wrong to gather it?
Now, what is the law's position on this much-debated matter? Let’s dive into the highest profile case of hiQ Labs vs LinkedIn to see if we can get some answers.
The Verdict: Scraping Data is not Unlawful
In 2022, the Ninth Circuit Court of Appeals finally made its decision and sided with hiQ Labs. The court held that scraping publicly available data does not amount to a violation of CFAA, even if it is against the terms of use of the website.
LinkedIn was attempting to prevent hiQ's bots from scraping data from its users' public profiles. But the Ninth Circuit was clear: giving a company the complete monopoly of data that it doesn’t own (as it is licensed) would be detrimental for the public interest.
A Limited Scope for the CFAA
In much simpler words, the Ninth Circuit established that companies do not have free rein over who can collect and use public data.
One must not interpret the CFAA so broadly, as it would make almost anyone a criminal.
Under the ruling, the CFAA only criminalizes unauthorized access to private, protected information.
To sum up: websites can no longer use the CFAA to prevent unauthorized data collection. And they cannot employ legal tools against scrapers.
The Public vs Private Data: Examining Legality Concerns
Data scraping legal concerns now shift towards the distinction between public-private data.
So, for your convenience, I prepared a short cheat sheet you should follow when you are planning to scrape data:
- Is the data freely available? You are probably safe.
- Is the data only available to owners? This could lead to trouble
Easy right?
But, there are some other factors we have to consider…
Even if the scraped data is publicly available, you still have to take into account contracts, copyright, and laws, like the GDPR if you’re in the EU.
There are also ethical considerations beyond just legality like respecting robots.txt instructions and avoiding overloading servers, to name a few. Just because something is “legal” does not make it instantly right.
A Green Light for Web Scrapers?
Although at first you may think the ruling favoring hiQ is a win for web scrapers, it doesn’t mean you have an open ticket to scraping.
This case narrows the CFAA's interpretation and affirms the right to gather public data. But, there are other data scraping legal issues we have to avoid.
For instance, if for scraping data you create a user account, then you can be in trouble as you have agreed with the terms of service. Even if the CFAA does not apply, one can be in breach of contract. What contract, you ask? Well, when you create a user account on a website, you typically have to agree to their terms of service.
Lastly, LinkedIn obtained a permanent injunction, which in English means that it got hiQ to desist scraping as part of the agreement they’ve reached. So, it kind of was also a victory for LinkedIn too.
PS: Keep in mind that scraping copyrighted data, like articles, videos, and images, can infringe on intellectual property rights, regardless of whether the data is publicly accessible.
Legal Implications of Web Scraping: The Bottom Line
“To scrape, or not to scrape - that is the question” as Hamlet would say - if he was born in 1998. Jokes aside, cases like hiQ vs LinkedIn helps us get some guidance on the legalities of web scraping.
It is highly improbable that scraping public data will cause you to violate the CFAA.
However, some practices could lead you to legal repercussions, such as disregarding cease-and-desist orders, breaching user agreements, and even creating fake accounts.
The six-year-old LinkedIn vs hiQ lawsuit may be over, but the war on data scraping is still ongoing. Companies will try to protect their data, and we all know how powerful lobbyists are in the US.
In the EU, however, lobbying might not be as big of an issue. Instead, for whatever reason, they've gone all-in on privacy, and I'm pretty sure the GDPR laws might have something to say about the use of web scraping.
Despite these challenges, we all know scrapers are gonna scrape.
Disclaimer:
A) Not legal advice. This post was written for educational and entertainment purposes.
B) While the hiQ vs LinkedIn case set a precedent, it doesn't give unrestricted freedom.
C) Data protection laws like GDPR in the EU will have priority over an American case.
D) Laws in your country could be entirely different from what’s mentioned in this text.
E) I’m not a lawyer, I have no idea what I’m dooiiinng.
References:
López de Letona, Javier Torre de Silva y. “The Right to Scrape Data on the Internet: From the US Case hiQLabs, Inc. v. LinkedIn Corp. to the ChatGPT Scraping Cases: Differences Between US and EU Law.” Global Privacy Law Review (2024) https://doi.org/10.54648/gplr2024001
Sobel, Benjamin. “HiQ v. LinkedIn, Clearview AI, and a New Common Law of Web Scraping.” (2020). https://dx.doi.org/10.2139/ssrn.3581844
https://proxycompass.com/data-scraping-legal-issues-exploring-hiq-vs-linkedin-case/








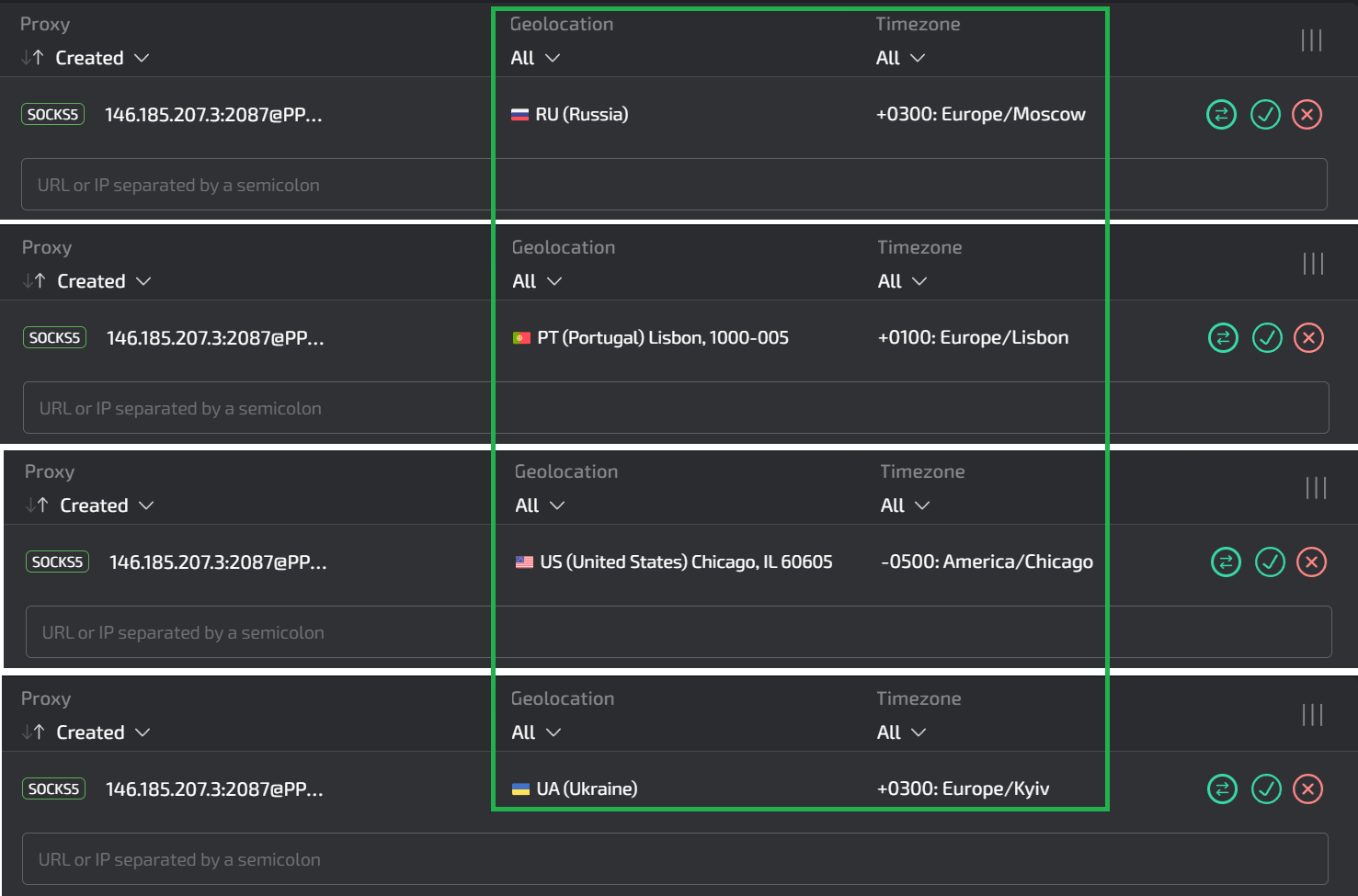
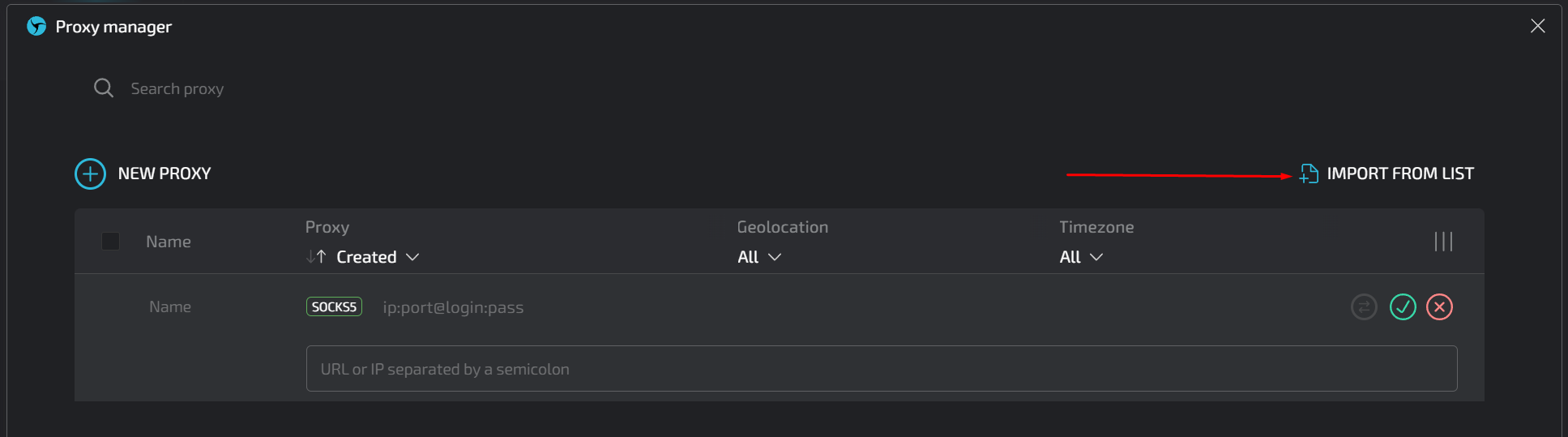
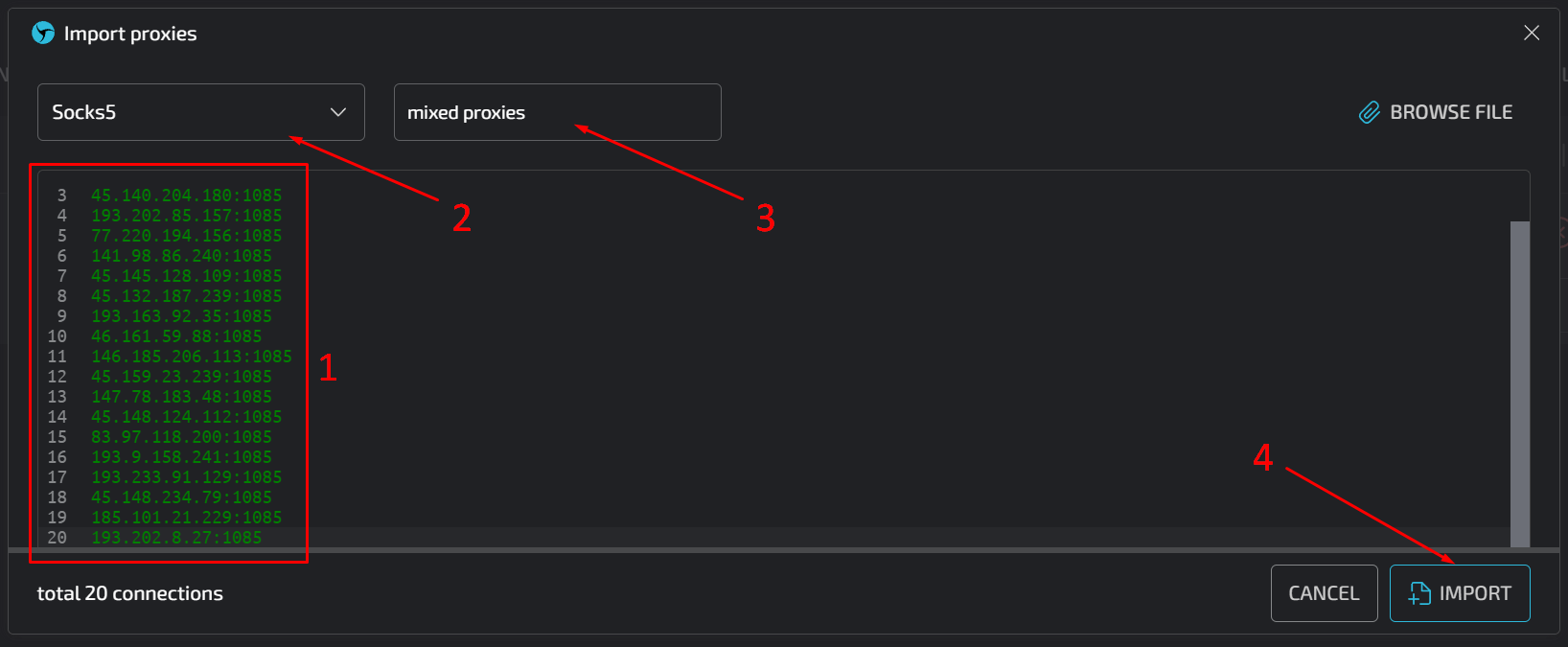
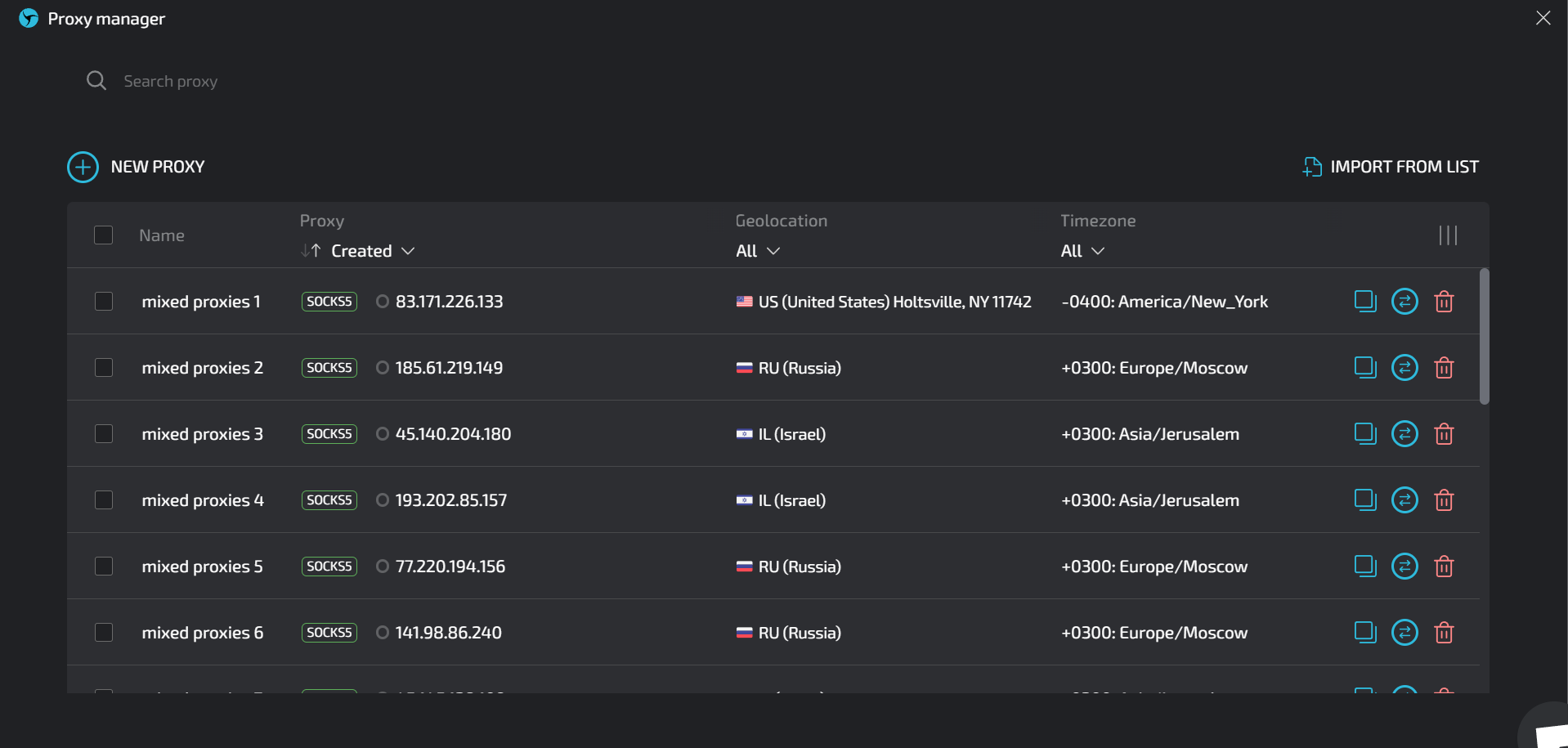
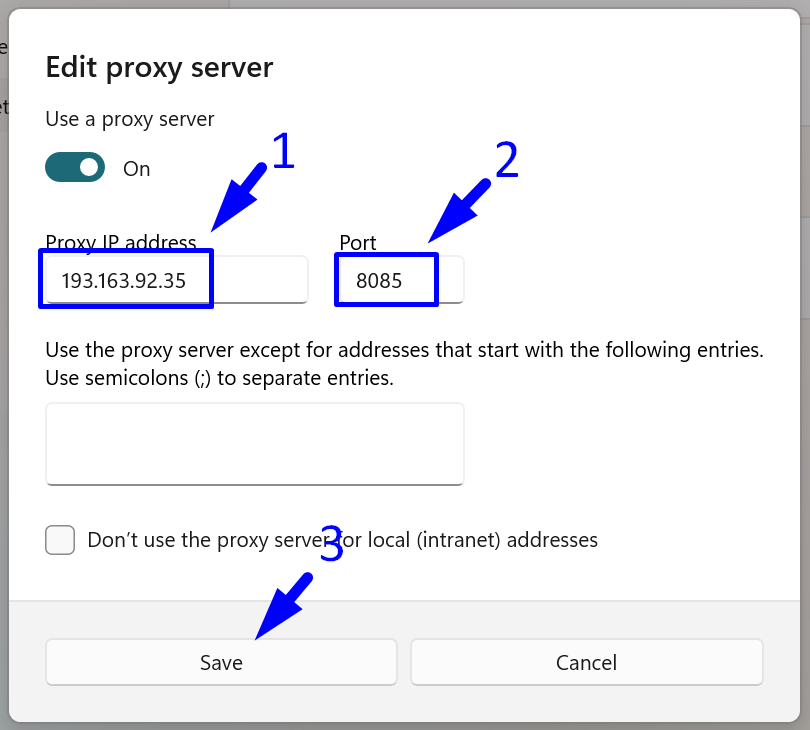
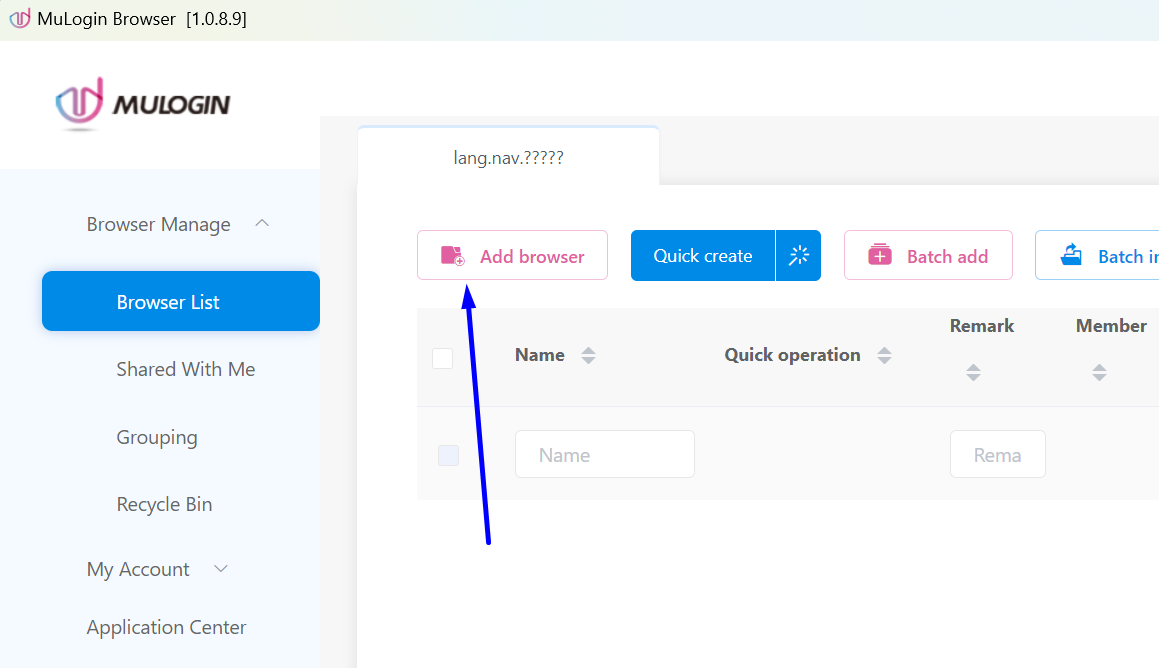
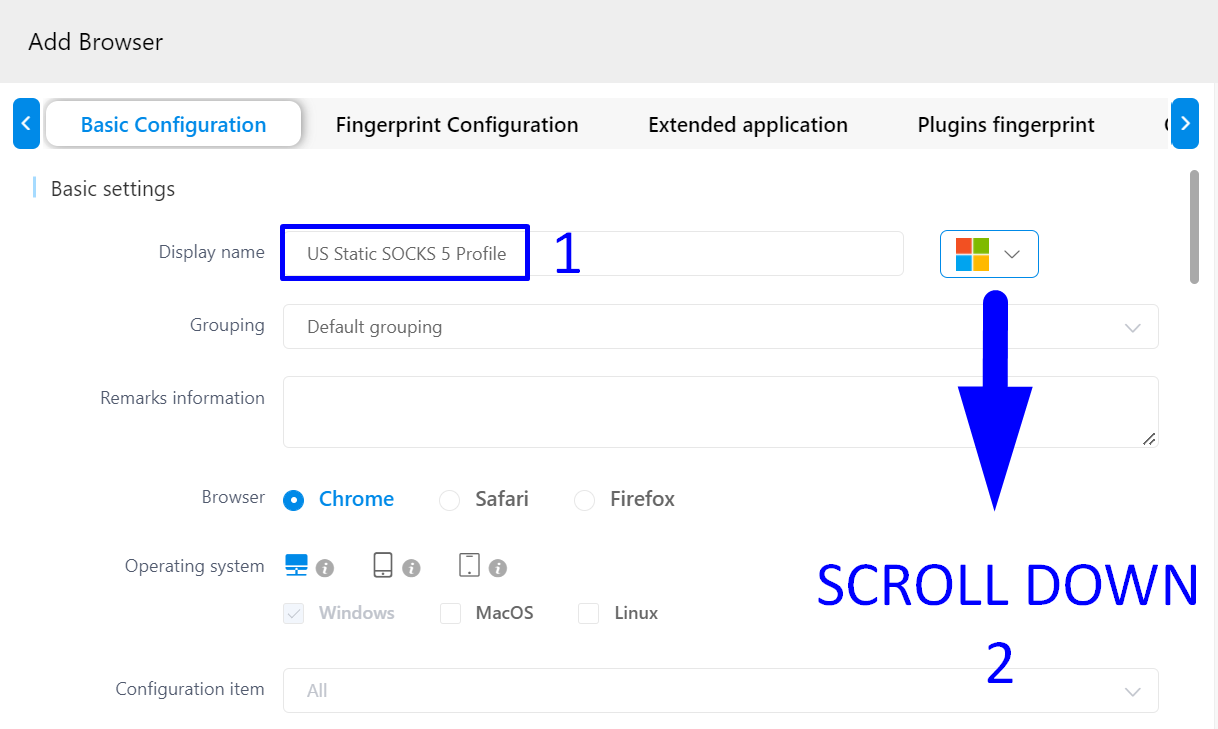
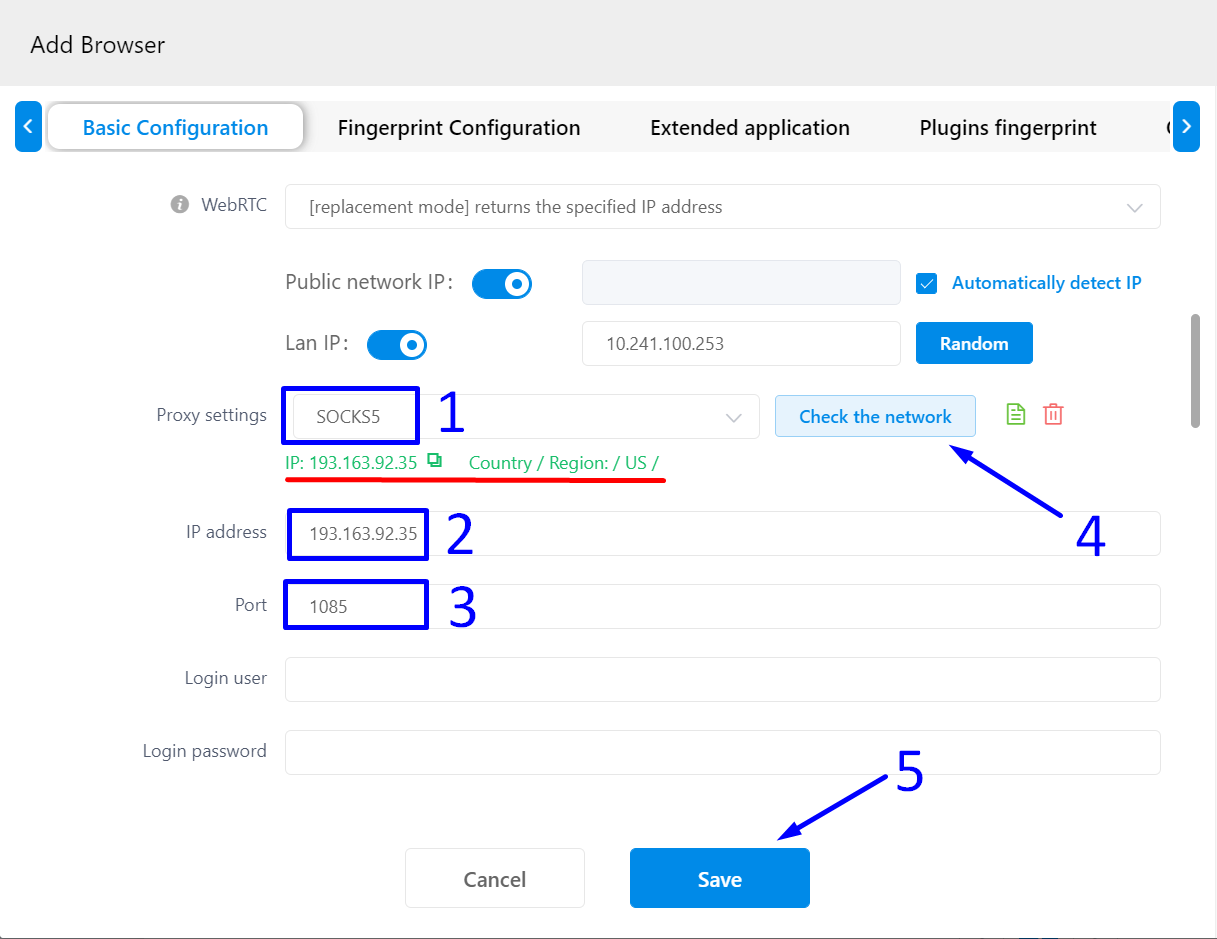
 several times, you should see a display similar to the one in the screenshot below:
several times, you should see a display similar to the one in the screenshot below: